Milvus(矢量数据库) v1.1.0 官方版

软件介绍
Milvus是一个绿色安全、免费开源的矢量数据库,支持针对TB级向量的增删改操作和近实时查询,可让用户对数据库内的所有数据进行搜索和浏览编辑,该软件拥有类似于智能的向量搜索引擎,可让用户对相似性数据进行搜索,可让用户更快更便捷的获取非结构化数据;Milvus部署灵活、稳定可靠,且具备操作便捷以及高速查询等特性,在全球范围内已被数百家组织和机构所使用,该软件支持标量数据过滤,可让用户更快速精准地获取指定数据,非常简单实用,有需要的用户可以自行下载。

软件功能
异构计算
优化了基于 GPU 搜索向量和建立索引的性能。
可以在单台通用服务器上完成对 TB 级数据的毫秒级搜索。
动态数据管理。
支持主流索引库、距离计算方式和监控工具
集成了 Faiss、NMSLIB、Annoy 等向量索引库。
支持基于量化的索引、基于图的索引和基于树的索引。
相似度计算方式包括欧氏距离 (L2)、内积 (IP)、汉明距离、杰卡德距离等。
Prometheus 作为监控和性能指标存储方案,Grafana 作为可视化组件进行数据展示。
近实时搜索
插入 Milvus 的数据默认在 1 秒后即可被搜索到。
标量字段过滤
支持向量和标量数据。
可以对标量数据进行过滤,增强搜索的灵活性。
软件特色
全面的相似度指标
Milvus 支持各种常用的相似度计算指标,包括欧氏距离、内积、汉明距离和杰卡德距离等。您可以根据应用需求来选择最有效的向量相似度计算方式。
业界领先的性能
Milvus 基于高度优化的 Approximate Nearest Neighbor Search (ANNS) 索引库构建,包括 faiss、 annoy、和 hnswlib 等。您可以针对不同使用场景选择不同的索引类型。
动态数据管理
您可以随时对数据进行插入、删除、搜索、更新等操作而无需受到静态数据带来的困扰。
近实时搜索
在插入或更新数据之后,您可以几乎立刻对插入或更新过的数据进行搜索。Milvus 负责保证搜索结果的准确率和数据一致性。
高成本效益
Milvus 充分利用现代处理器的并行计算能力,可以在单台通用服务器上完成对十亿级数据的毫秒级搜索。
支持多种数据类型和高级搜索
Milvus 的数据记录中的字段支持多种数据类型。您还可以对一个或多个字段使用高级搜索,例如过滤、排序和聚合。
高扩展性和可靠性
您可以在分布式环境中部署 Milvus。如果要对集群扩容或者增加可靠性,您只需增加节点。
云原生
您可以轻松在公有云、私有云、或混合云上运行 Milvus。
简单易用
Milvus 提供了易用的 Python、Java、Go 和 C++ SDK,另外还提供了 RESTful API。
官方教程
确认Docker状态确认Docker守护程序在后台运行:
$ sudo docker info
Copy
如果看不到列出的服务器,请启动Docker守护程序。
在Linux上,Docker需要sudo特权。要在没有sudo特权的情况下运行Docker命令,请创建一个docker组并添加您的用户(有关详细信息,请参阅Linux的安装后步骤)。
拉Docker镜像拉出仅CPU的映像:
$ sudo docker pull milvusdb/milvus:1.1.0-cpu-d050721-5e559c
如果由于网络限制而无法使用主机在线获取Docker映像和配置文件,请从另一台可用主机在线获取它们,将它们另存为TAR文件,将其传递到本地计算机上,然后将TAR文件加载为Docker映像:
单击此处查看示例代码。
如果拉docker镜像的速度太慢或失败,请参阅操作常见问题解答以获取解决方案。
下载配置文件

如果无法通过wget命令下载配置文件,则可以在/ home / $ USER / milvus / conf下创建server_config.yaml文件,然后将内容从服务器配置复制到该文件。
启动Docker容器启动Docker容器并将映射到本地文件的路径映射到该容器:
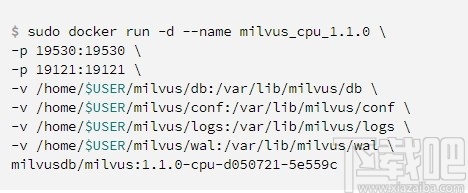
docker run上面命令中使用的选项定义如下:
-d:在后台运行容器并打印容器ID。
--name:为容器分配一个名称。
-p:将容器的端口发布到主机。
-v:将目录安装到容器中。
确认Milvus的运行状态:
$ sudo docker ps
如果Milvus服务器无法正常启动,请检查错误日志:
$ sudo docker logs milvus_cpu_1.1.0成功启动Milvus服务器后,可以使用此示例程序创建表,插入10个向量,然后运行向量相似度搜索。确保已安装Python 3.6和兼容的pip。安装Milvus Python SDK。# Install Milvus Python SDK
$ pip3 install pymilvus==1.1.0
Copy要了解有关Milvus Python SDK的更多信息,请访问Milvus Python SDK自述文件。下载Python示例代码。# Download Python example
$ wget https://raw.githubusercontent.com/milvus-io/pymilvus/v1.1.0/examples/example.py
Copy如果您不能wget用来下载示例代码,则还可以创建example.py并复制示例代码。运行示例代码。# Run Milvus Python example
$ python3 example.py
Copy确认程序运行正常。Query result is correct.
Copy恭喜你!您已成功完成与Milvus的首次矢量相似度搜索。连接到服务器本文介绍如何从Python客户端连接到Milvus服务器。有关API的详细信息,请参见Python API文档。我们建议使用Milvus大小调整工具来估计数据所需的硬件资源。导入pymilvus:# Import pymilvus.
>>> from milvus import Milvus, IndexType, MetricType, Status
Copy使用以下任何一种方法连接到Milvus服务器:# Connect to the Milvus server.
>>> milvus = Milvus(host='localhost', port='19530')
Copy在上面的代码,host并且port都使用的默认值。您可以将它们更改为您的IP地址和端口。>>> milvus = Milvus(uri='tcp://localhost:19530')创建一个集合准备创建集合所需的参数:# Prepare collection parameters.
>>> param = {'collection_name':'test01', 'dimension':256, 'index_file_size':1024, 'metric_type':MetricType.L2}
Copy创建一个名为的集合test01,其大小为256,索引文件大小为1024 MB。它使用欧几里德距离(L2)作为距离测量方法。# Create a collection.
>>> milvus.create_collection(param)
Copy删除收藏集# Drop a collection.
>>> milvus.drop_collection(collection_name='test01')创建分区为了提高搜索效率,您可以按标签将集合划分为几个分区。实际上,每个分区都是一个集合。# Create a partition.
>>> milvus.create_partition('test01', 'tag01')
Copy删除分区>>> milvus.drop_partition(collection_name='test01', partition_tag='tag01')将向量插入集合随机生成20个256维向量:>>> import random
# Generate 20 vectors of 256 dimensions.
>>> vectors = [[random.random() for _ in range(256)] for _ in range(20)]
Copy插入向量列表。如果您未指定矢量ID,则Milvus会自动将ID分配给矢量。# Insert vectors.
>>> milvus.insert(collection_name='test01', records=vectors)
Copy您还可以指定矢量ID:>>> vector_ids = [id for id in range(20)]
>>> milvus.insert(collection_name='test01', records=vectors, ids=vector_ids)
Copy将向量插入分区>>> milvus.insert('test01', vectors, partition_tag="tag01")
Copy通过ID删除载体假设您的集合包含以下向量ID:>>> ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
Copy您可以使用以下命令删除向量:>>> milvus.delete_entity_by_id(collection_name='test01', id_array=ids)
Copy调用之后delete,您可以flush再次调用以确保新插入的数据可见,并且删除的数据不再可恢复。创建一个索引当前,集合仅支持一种索引类型。当您更改集合的索引类型时,Milvus会自动删除旧的索引文件。在创建其他索引之前,集合使用FLAT作为默认索引类型。create_index()指定集合的索引类型,并为先前插入的数据同步创建索引。当随后插入的数据的大小达到时index_file_size,Milvus会在后台自动创建索引。对于流数据,建议在插入向量之前创建索引,以便系统可以自动为下一个数据建立索引。对于静态数据,建议先导入所有数据,然后创建索引。有关使用索引的详细信息,请参见“索引示例程序”。准备创建索引所需的参数(以IVF_FLAT为例)。索引参数存储在JSON字符串中,该字符串由Python SDK中的字典表示。# Prepare index param.
>>> ivf_param = {'nlist': 16384}
Copy不同的索引类型需要不同的索引参数。他们必须都有一个值。为集合创建索引:# Create an index.
>>> milvus.create_index('test01', IndexType.IVF_FLAT, ivf_param)
Copy删除索引删除索引后,集合将再次使用默认索引类型FLAT。>>> milvus.drop_index('test01')进行矢量搜索Milvus支持在集合或分区中搜索向量。在集合中搜索向量创建搜索参数。搜索参数存储在JSON字符串中,该字符串由Python SDK中的字典表示。>>> search_param = {'nprobe': 16}
Copy不同的索引类型需要不同的搜索参数。您必须为所有搜索参数分配值。有关更多信息,请参见向量索引。创建随机向量以query_records进行搜索:# Create 5 vectors of 256 dimensions.
>>> q_records = [[random.random() for _ in range(256)] for _ in range(5)]
>>> milvus.search(collection_name='test01', query_records=q_records, top_k=2, params=search_param)
Copytop_k表示搜索与目标向量最相似的k个向量。它是在搜索过程中定义的。的范围top_k是[1,16384]。在分区中搜索向量# Create 5 vectors of 256 dimensions.
>>> q_records = [[random.random() for _ in range(256)] for _ in range(5)]
>>> milvus.search(collection_name='test01', query_records=q_records, top_k=1, partition_tags=['tag01'], params=search_param)
Copy如果未指定partition_tags,Milvus将在整个集合中搜索相似的向量。
常见问题
为什么Milvus重新启动后第一次搜索要花很长时间?
这是因为重新启动后,Milvus需要将磁盘中的数据加载到内存中以进行第一个矢量搜索。您可以preload_collection在server_config.yaml中进行设置,并在内存允许的情况下加载尽可能多的集合。Milvus每次重新启动时都会将集合加载到内存中。否则,您可以调用load_collection()将集合加载到内存中。
为什么搜索速度很慢?
检查的值cache.cache_size在server_config.yaml比集合的大小。
如何改善Milvus的表现?
确保值cache.cache_size在server_config.yaml比集合的大小。
确保所有段均已建立索引。
检查服务器上是否还有其他消耗CPU资源的进程。
调整的数值index_file_size和nlist。
如果搜索性能不稳定,则可以-e OMP_NUM_THREADS=NUM在启动Milvus时添加NUM,该数量是CPU内核数的2/3。
如何设置nlist和nprobe试管婴儿索引?
一般而言,的推荐值nlist是4 × sqrt(n),其中n是段中实体的总数。
确定nprobe是在搜索性能和准确性之间进行权衡的依据,它取决于您的数据集和方案。建议运行几轮测试以确定的值nprobe。
以下图表来自在sift50m数据集和IVF_SQ8索引上运行的测试。测试比较了搜索性能与不同之间的召回率nlist/nprobe对。
更新日志
新的功能#4564支持在get_entity_by_id()方法调用中指定分区。
#4806支持在delete_entity_by_id()方法调用中指定分区。
#4905添加release_collection()方法,该方法从缓存中卸载特定的集合。
改进之处#4756提高get_entity_by_id()方法调用的性能。
#4856将hnswlib升级到v0.5.0。
#4958提高IVF指数训练的性能。
已解决的问题#4778无法访问Mishards中的向量索引。
#4797在合并具有不同topK参数的搜索请求后,系统返回错误结果。
#4838服务器没有立即对空集合上的索引建立请求做出响应。
#4858对于启用GPU的Milvus,系统在搜索请求数量较大topK(> 2048)时崩溃。
#4862只读节点在启动过程中会合并段。
#4894布隆过滤器的容量不等于其所属网段的行数。
#4908删除集合后,无法清理GPU缓存。
#4933系统花很长时间才能为一小段建立索引。
#4952无法将时区设置为“ UTC + 5:30”。
#5008在连续,并发删除,插入和搜索操作期间,系统随机崩溃。
#5010对于启用GPU的Milvus,如果nbits≠8 ,查询将无法在IVF_PQ上执行。
#5050 get_collection_stats()为仍在建立索引过程中的段返回错误的索引类型。
#5063清空空段时,系统崩溃。
#5078对于启用GPU的Milvus,在2048、4096或8192维的向量上创建IVF索引时,系统崩溃。
本类最新
-
CKplayer网页播放器
336 KB/2020-08-17ckplayer是一款在网页上播放视频的免费的网页播放器,功能强大,体积小巧,跨平台,使用起来随心所欲。CKplayer网页播放器主要以adobe的flash(所使用的版本是CS5)平台开发,ckplayer同时也支持html5的视频播放。
-
WordPress
6.7 MB/2020-08-17WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设自己的网志。也可以把WordPress当作一个内容管理系统(CMS)来使用。
-
Discuz论坛
4.05 MB/2020-08-17Discuz!Board(以下简称Discuz!,中国国家版权局著作权登记号2003SR6623)是一个通用的论坛软件系统,用户可以在不需要任何编程的基础上,Discuz论坛通过简单的设置和安装
-
Guns后台管理系统
12.5 MB/2020-08-17Guns后台管理系统是一款项目快速开发管理系统网站搭建模板,基于SpringBoot2开发,内置主控面板、组织架构、用户管理、机构管理、职位管理、权限管理、基础数据、系统功能
-
狂雨小说cms
7.8 MB/2020-08-17狂雨小说是一款体积轻量、简单易用的轻量级小说网站搭建模板,基于ThinkPHP5.1+MySQL的技术开发,网站搭建和部署便捷简单,通过该模板用户可以快速搭建一个属于自己的小说内
-
Slidev(开发幻灯片展示)
8.52 MB/2020-08-17Slidev是一款非常专业且优秀的开发幻灯片展示软件,作为基于Web的幻灯片制作和演示软件,非常适合开发人员使用,可帮助他们专注于在Markdown中编写内容,软件功能强大,拥有HTML
-
魔众短链接系统
27.5 MB/2020-08-17魔众短链接系统是一款绿色安全、免费开源的短链接生成网站搭建模板,基于PHP+Mysql开发,可帮助用户快速搭建属于自己的短链接生成网站,该网站界面简洁美观、对SEO非常友好,功
-
易语言资源网源码下载工具
1.51 MB/2020-08-17易语言资源网源码下载工具是一款对开发者极为有用的易语言源码查找工具,用户可以通过这款工具在易语言资源网中查找各种项目的源码;很多开发者在开发项目时会在网上查找一













- 一周最热
- 总排行榜
-
2
建站专家网站建设系统
-
3
Turbo C 2.0库函数速查
-
4
PPTV网络电视系统
-
5
中英繁公司企业智能自助建站源码
-
6
宾馆酒店饭店网站建设模板ASP源码
-
7
XOOPS 简体中文版 2.0.3 for Unix
-
8
SaurusCMS
-
9
Deluge For Linux
-
10
及速自助网站建设系统









-
2
82699天下棋牌最新版
-
3
松江一道棋牌手机版
-
4
8236天下棋牌最新版
-
5
82699天下棋牌下载
-
6
大连娱网棋牌打滚子下载
-
7
太阳城棋牌app最新版
-
8
太阳城棋牌app安卓版
-
9
太阳城棋牌app官方版
-
10
西元棋牌捞腌菜安卓版2025
您可能感兴趣的专题
-

男生必备
男生们看过来!
-

安卓装机必备
-

女生必备
女生必备app是拥有众多女性用户的手机软件,作为一个女生,生活中像淘宝、京东这类线上购物软件可以说是少不了的,小红书这种穿搭、化妆分享平台也很受欢迎,类似于西柚大姨妈、美柚这种专为女生打造的生理期app更是手机必备,还有大家用的最多拍照美颜app是绝对不能忘记的,除此之外对于一些追星女孩来说,微博也是一个必不可少的软件。超多女生必备软件尽在下载吧!
-

迅雷看看使用教程
迅雷看看播放器是一款多功能在线高清多媒体视频播放器,支持本地播放与在线视频点播,采用P2P点对点传输技术,可以在线流畅观看高清晰电影。不仅如此,迅雷看看不断完善用户交互和在线产品体验,让您的工作与生活充满乐趣。
-

驱动精灵
驱动精灵是一款集驱动管理和硬件检测于一体的、专业级的驱动管理和维护工具。驱动精灵为用户提供驱动备份、恢复、安装、删除、在线更新等实用功能,也是大家日常生活中经常用到的实用型软件之一了。
-

拼音输入法
对于电脑文字输入,拼音输入法是一种非常受欢迎的输入法,搜狗拼音输入法、百度拼音输入法、QQ拼音输入法、谷歌拼音输入法、紫光拼音输入法、智能拼音输入法等,你在用哪款呢?一款好用适合自己的拼音输入法一定对您平时帮助很大!下载吧收集了最热门国人最喜欢用的拼音输入法给大家。
-

b站哔哩哔哩怎么使用
很多人都喜欢在b站哔哩哔哩上观看视频,不单是因为可以提前看到一些视频资源,B站的一些弹幕、评论的玩法也是被网友们玩坏了!下面下载吧小编带来了b站哔哩哔哩怎么使用的教程合集!希望能帮到你啦!
-

抖音短视频app
抖音短视频app,这里汇聚全球潮流音乐,搭配舞蹈、表演等内容形式,还有超多原创特效、滤镜、场景切换帮你一秒变大片,为你打造刷爆朋友圈的魔性短视频。脑洞有多大,舞台就有多大!好玩的人都在这儿!